langyu
- 浏览: 883681 次
- 性别:

- 来自: 杭州
-

最新评论
-
u013146595:
楼主你人呢,搬家了吗。还想看你的文章
读代码的“深度优先”与“广度优先”问题 -
zjut_ywf:
写的不错,比书上还具体,受益匪浅
MapReduce:详解Shuffle过程 -
sxzheng96:
seandeng888 写道Combiner阶段应该是在Par ...
MapReduce:详解Shuffle过程 -
sxzheng96:
belivem 写道你好,大神,我也是这一点不是很清楚,看了你 ...
MapReduce:详解Shuffle过程 -
jinsedeme0881:
引用77 楼 belivem 2015-07-11 引用你 ...
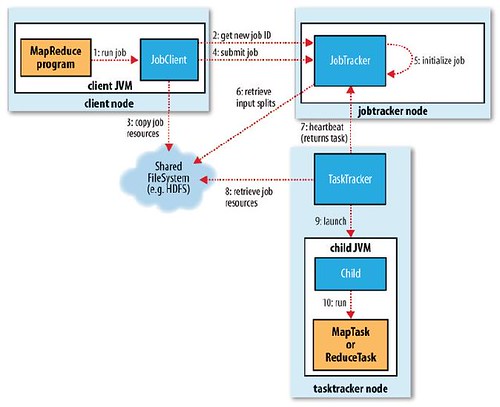
MapReduce:详解Shuffle过程



相关推荐
MapReduce Job集群提交过程源码跟踪及分析
MapReduce Job本地提交过程源码跟踪及分析
我们基于Hadoop1.2.1源码分析MapReduceV1的处理流程。MapReduceV1实现中,主要存在3个主要的...在编写好MapReduce程序以后,需要将Job提交给JobTracker,那么我们就需要了解在提交Job的过程中,在JobClient端都做了哪
hadoop 搭建过程
重点介绍了Hadoop MapReduce的工作机制,并以作业提交、作业初始化、任务分配、任务执行和任务进度更新等流程介绍了Job Client、JobTracker、TaskTracker和HDFS在MapReduce过程中的分工与协作,最后,对云计算作出展望...
058 MapReduce提交作业源码跟踪讲解 059 MR作业运行流程整体分析 060 MapReduce执行流程之Shuffle和排序流程以及Map端分析 061 MapReduce执行流程之Reduce端分析 062 MapReduce Shuffle过程讲解和Map Shuffle Phase...
matlab聚类kmeans代码 作业7 要求 在MapReduce上实现K-Means算法并在小数据集上测试。可以使用附件的数据集,也可以随机生成若干散点的二维...依次调用三个主要的过程: generateInitialCluster():随机产生k个cluster
Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为...
Spark是UC Berkeley AMP Lab(加州⼤学伯克利分校的 AMP实验室)所开源的类Hadoop MapReduce的通⽤并⾏框架,它拥有Hadoop MapReduce所具有的优 点,但不同MapReduce的是,Job中间输出结果可以保存在内存中,从⽽不...
手把手视频详细讲解项目开发全过程,需要的小伙伴自行百度网盘下载,链接见附件,永久有效。 课程简介 从零开始讲解大数据调度系统构成,集成大数据计算任务构建大数据工作流,基于Oozie构建实现企业级自动化任务...
90_job提交流程剖析 91_job split计算法则-读取切片的法则 92_job seqfile5 v! h+ R9 L1 w, U* T6 J# M 93_job 全排序-自定义分区类2 n% h" `: b4 c) C3 J9 S 94_job二次排序5 t3 Z2 R- ]( a: s* c0 Z 95_从db输入...